![[LBNL]](/images/lbnl_new.jpeg)
|
|
Berkeley UPC - Unified Parallel C |
|
This is a design document for the implementation of memory management in the runtime layer of the Berkeley UPC compiler. The external API for the runtime layer (as seen by compiler-generated code) is documented in the UPC Runtime Specification.
| Prefix | Meaning |
| upc_ | indicates a UPC language-level symbol |
| upcr_ | indicates a symbol in the runtime system not visible to the UPC programmer (called by compiler-generated code) |
| upcri_ | indicates a symbol in the runtime system not visible outside the runtime system (called only within the runtime) |
| gasnet_ | indicates a routine in the GASNet communication system (not visible to users or compiler: called by runtime functions) |
On pure shared memory machines, shared memory (and interprocess mechanisms such as pthreads/SysV IPC synchronization) is used to perform all interthread communication.
In this model, the UPC runtime will reply upon the network (i.e. the GASNet layer) for all inter-thread communications.
On CLUMPs ("clusters of SMPs"), multiple threads/processes will exist on each of multiple nodes. In this environment, shared memory will be used for communication between pthreads/processes on the same node, and GASNet will be used for communication between nodes.
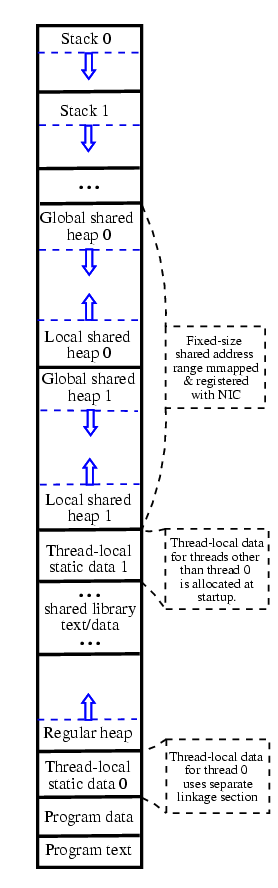 The diagram on the right shows a possible layout for the memory regions of a
single process that is implementing 2 UPC threads (via 2 pthreads): the
sections need not necessarily be in the order specified. A UPC that only
implements a single UPC thread would not use pthreads, and would thus only have
1 stack, 1 global and local shared heap, and no thread-local data sections.
The diagram on the right shows a possible layout for the memory regions of a
single process that is implementing 2 UPC threads (via 2 pthreads): the
sections need not necessarily be in the order specified. A UPC that only
implements a single UPC thread would not use pthreads, and would thus only have
1 stack, 1 global and local shared heap, and no thread-local data sections.
When pthreads are not used, the user's static/global unshared variables simply exist as regular C static/global variables in the program data section.
The shared memory region needs to be allocated specially for many network interfaces (the pages may need to be pinned in memory, and/or DMA registration may need to occur, etc.), and so the entire region is allocated for the runtime by GASNet as part of the gasnet_attach() call. GASNet may or may not allocate physical memory for the shared region (it may just mmap some virtual memory to be allocated on first write). It must be guarantee, however, that the memory area returned is legal to reference at any time after gasnet_attach without causing a segmentation fault (this constraint considerably reduces the communication requirements needed for the UPC global shared memory allocation functions--see below).
UPC programs will generally be compiled statically: however, there may be cases in which dynamic shared libraries will be loaded, and the location where they are put may not be under the control of the UPC runtime or GASNet. Most operating systems have a standard address at which they start performing the mmaps of shared library contents (the x86 Linux loader, for instance, starts loading shared objects starting at address 0x40000000, leaving wide gaps between the loaded libraries' address spaces and those of the stack and default heap). Depending on the amount of shared memory that is needed in a program, this default location may make it difficult to find a large enough contiguous region in which to place the shared memory region (particularly on 32 bit machines).
Dealing with this issue is left to GASNet: the runtime merely requests a shared region of a specific size (with a guaranteed heap offset, as discussed next), and GASNet either provides it or returns an error.
To support malloc implementations that simply fail once sbrk ceases to provide more memory space, the gasnet_attach function will take a parameter that guarantees a certain spacing between the shared heap area and the beginning of the regular heap. This will guarantee that the shared region (at least) will not limit the size of the regular heap. Users will be able to specify the size of this region via environment variables and/or command line flags.
As can be seen from the diagram above, each UPC thread will make use of 3 separate memory heaps. If a UPC process uses pthreads, the pthreads will share a single regular heap, but will each have separate shared global and shared local heaps. The following table summarizes which types of allocations reside in which heap:
| Heap | Types of Allocations | Example |
| Global shared heap | UPC shared allocations that result in phased memory blocks that stripe across nodes | Any call to upc_global_alloc or upc_all_alloc in which the block size is less than the size of the allocated memory (i.e. any such memory that doesn't exist only on thread 0). Static UPC arrays with the same property. |
| Local shared heap | UPC shared memory that is allocated to exist only on a single node/thread | All calls to upc_alloc. Memory allocated by upc_all_alloc and/or upc_global_alloc that exists entirely on node 0 (i.e. has a block size larger than the allocated size). Static shared data with the same property. |
| Regular heap | Unshared memory from standard calls to malloc(), etc. | Malloc, calloc, realloc, etc. |
Note that since static shared data will be implemented using dynamic allocations at startup--as explained in the notes on static user data--it will exist in the heaps, rather than in a regular data segment.
In the functions below <AT> stands for the allocator type, which may be one of: 'sharedglobal', 'sharedlocal', or 'local'. upcra_ stands for UPC Runtime Allocator API, a different name since this is not intended to be called by compiler-generated code, which will use only the global_alloc, etc., style functions.
upcra_<AT>_heap_t* upcra_<AT>_init(void *heapstart, uintptr_t initbytes);
Called by upcr once during startup (during upcr_init) to initialize each allocator before any other calls to the allocator. heapstart points to the start of the allocator's heap, and initbytes provides an initial size for the heap. The return value is a pointer to a heap structure, which is passed to the other functions to specify which heap is to be used.
void *upcra_<AT>_alloc(upcra_<AT>_heap_t* heap, size_t numbytes);
Allocates a region of numbytes bytes from the appropriate heap and return a pointer to the allocated memory, which is suitably aligned for any kind of variable. The memory is not cleared.Returns NULL to indicate that the allocator has run out of free memory and either some memory frees must take place or the allocator needs to be provided with additional pages (using upcra_provide_pages_<AT>()) before a request for numbytes can be satisfied.
void upcra_<AT>_free(upcra_<AT>_heap_t* heap, void *ptr);
Free the region of memory indicated by ptr, which was previously returned by a call to upcra_alloc_<AT> on this same allocator. Allocators that optionally choose to detect deallocation errors (e.g. duplicate free calls) should print an error message to stderr and call abort() when an error is detected.
void upcra_<AT>_provide_pages(upcra_<AT>_heap_t* heap, uintptr_t numbytes);
The runtime may call this function at any time to provide additional unused memory pages to the allocator. The allocator will be told it has an additional amount of 'numpages' pages of memory to use (the amount provided will always be a multiple of the system's page size). This new memory will start from the previous end address of the heap (if the global heap grows down, the new memory comes from the bottom end of the heap).Finally, if the allocator for the global shared heap cannot support growing the address range for the heap downward instead of upward, UPCR_GLOBALHEAP_GROWS_UP must be #defined, as the logic for detecting global/local heap collision is different in that case.This function will often be called after a failed call to upcra_alloc_<AT> which indicates the allocator requires more pages.
The runtime is responsible for ensuring that the address ranges given to the heaps are safe to access (and, for the shared heaps, have been registered with gasnet such that they can be accessed by remote nodes).
However, since user code may take an arbitrary amount of time in between calls to the UPC runtime, it is desirable to also have a method of asynchronously forcing incoming requests to be handled, if they have not been handled after a specified amount of time. The GASNet layer may thus cause a signal to be sent (presumably a SIGALRM), in order to force progress on requests. This may result in the handlers being run within a signal handler context.
Traditionally, code running in signal handler context is extremely circumscribed in what it can do: none of the standard pthreads/System V synchronization calls are on the list of signal-safe functions (for such a list see Richard Stevens' *Advanced Programming in the Unix Environment*, p 278). To overcome these limitations, and allow our handlers to be more useful, the normal limitations on signal handlers will be avoided through the use of "Handle-safe locks." All function calls that are not signal-safe and which are used within our handlers MUST be called within a GASNet critical section:
GASNET_CRITICAL_START
...
GASNET_CRITICAL_END
Critical sections are designed to be held briefly (no blocking, no network calls,
etc.). They guarantee that the code within the section will not be interrupted by
a signal-spawned GASNet-registered handler (if a signal arrives while the
critical section is in effect, the handler will be postponed until the critical
section is completed). This system guarantees that 'signal unsafe' (i.e.
non-reentrant) functions will not be called reentrantly, and so we may use them
even in handler code that may run in signal handler context.
Code that runs inside an asynchronous handler is implicitly within a GASNet critical section, so the START/END macro calls must not be used. Code that runs in regular context (including the user's UPC code) must use these macros whenever a signal-unsafe function is called. This means that the UPC runtime must intercept any such calls (like malloc. etc.), and redirect them to a version that wraps the standard library call with the GASNet critical section macros.
See the GASNet specification for details.
The issues involved with the regular heap have already been covered above (the UPC runtime must ensure that it does not tread into the shared memory area, and if the allocator for the local heap is not reentrant and pthreads are being used, the UPC runtime's wrapper versions of malloc, etc., must perform the needed locking).
The following diagram illustrates the mechanisms used for handling shared memory allocations (for clarity, the diagram is of a UPCR_PURE_DISTRIBUTED configuration, with one process per node: for a threaded implementation there would be two shared regions per process, as in the layout diagram above):
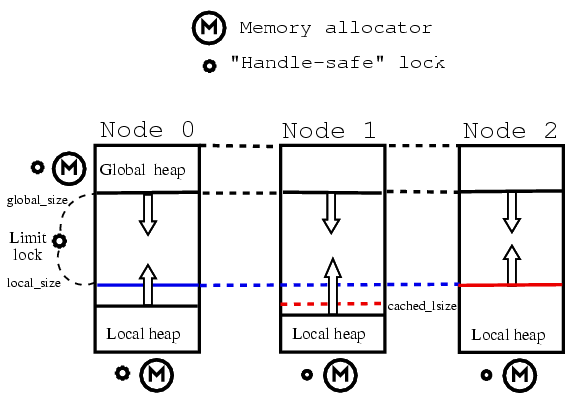
Each UPC thread has its own shared memory area, containing a local heap growing upward from the bottom, and a global heap growing down from the top. The size of the shared memory area for all threads will be the same, and will be allocated at startup.
Each thread maintains a separate allocator for its local shared heap, along with a handle-safe lock to protect it from concurrent accesses (since memory allocated via upc_alloc may have upc_free called on it asynchronously from another node, locking is required even for local shared heaps).
The global shared memory heaps of all threads are managed by a single allocator on thread 0, which makes decisions on behalf of all the threads. The layout of used/unused areas of the global portion is consistent across all the threads; although the starting/ending virtual addresses of the global heaps may be different (on pthreads implementations it must be, for instance) the size of the heap, and the offset of allocations within it will always the same for all global heaps in a UPC job.
Thread 0 also maintains two counters ('global_size' and 'local_size' in the diagram) that track the number of pages that have been handed out for the global and local heaps, respectively (for the local heap size, this is the size of the largest local heap of all the threads in the UPC job). These counters are monotonically increasing, since pages are never taken away from the heap sizes, only added. The counters exist to make sure that the global and local heaps never collide (if they are about to collide this is a fatal runtime error). The locks are protected by a single lock ("Limit lock" in the diagram): the values may be read without the lock (since they are guaranteed to only increase), but cannot be increased without holding the lock. Note that if both the limit-lock and either the global or local allocator locks on thread 0 need to be held at the same time, the limit lock must be grabbed after the local or global lock: this simple lock hierarchy prevents deadlock (we do not anticipate ever needing to hold all three locks at once, but if we do, then we'll need a lock hierarchy between the local and global locks as well).
Threads other than thread 0 will keep a local copy of the value of local_size ('cached_lsize' in the diagram). This value need not be in sync with the actual value of local_size, but provides a reliable minimum local stack size that local threads can rely on as valid, eliminating the need for some network traffic. This value does not need a lock (it can only be modified by upcr_local_allocs, which are guaranteed to be performed serially by any one thread).
With this diagram in mind, we can now outline pseudocode for each of the UPC runtime memory allocation functions.
upcr_shared_ptr_t* upcr_local_alloc(int nblocks, int blocksz)
So, for instance, in the diagram above, if Node 1 needs more pages for its local allocator, it may be able to give them to it without any network traffic, since it has a cached_lsize that exceeds its heap size. Node 2, however, will need to talk to node 0 to increase its local heap size, since it is already using all of the local heap space that it knows is valid.
Possible optimization: if an RPC request for more memory space is required, it may make sense to ask for more memory than is immediately needed, on the principle that allocations tend to come in groups, hence another allocation is likely to occur soon.
upcr_shared_ptr_t* upcr_all_alloc(int nblocks, int blocksz)
Possible optimization: each thread could "touch" (write) a location on each page of the newly allocated region before returning, thereby forcing all threads to page fault (if necessary) at the same time, maintaining better lockstep across processors. For very large allocations (where the size is on the same order as the physical memory size) this optimization would be skipped to prevent introducing thrashing behavior.
upcr_shared_ptr_t* upcr_global_alloc(int nblocks, int blocksz)
It will also be OK if during a upc_all_alloc, one node receives the broadcast address and immediately refers to the new memory on another node which has not yet even received the broadcast address (this is theoretically possible if the network allows messages to be delivered out of order).
These types of "refer to the memory on a node without the node knowing that is has been allocated" scenarios are OK, since GASNet guarantees that the entire shared memory region handed out to each thread at startup is valid to be referenced at any time after wards. It guarantees this interface even for networks which do not actually support allowing the entire shared region to be directly accessible at once in its entirely (see the GASNet specification for details).
This page last modified on Friday, 28-Oct-2022 15:49:55 PDT